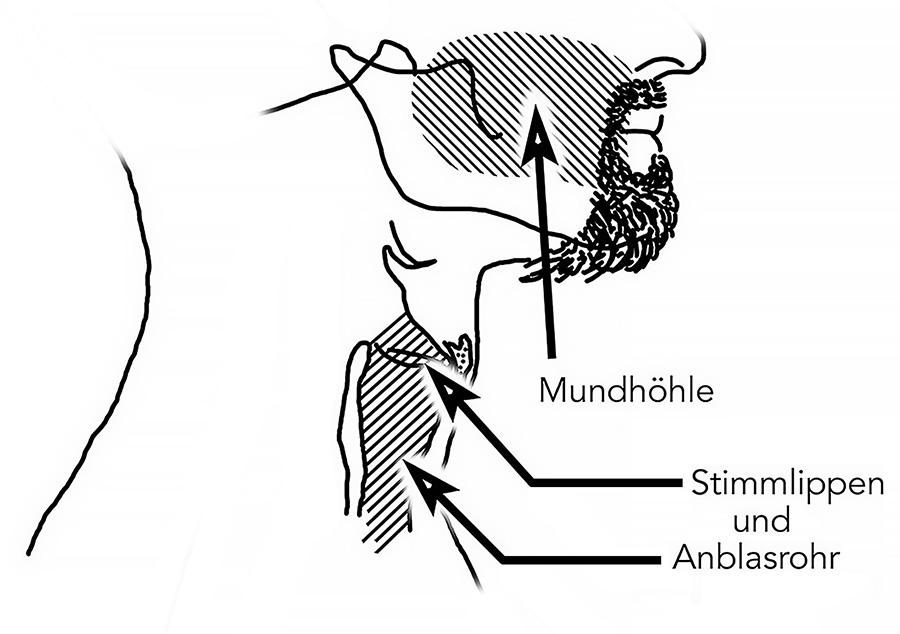
Vor allem ist Sprache ein Missverständnis – wann immer Sprache gleichgesetzt wird mit Stimme. Sprache ist eine Form der Kodierung, die mit den Stimmlippen – und also mit Stimme und Tonhaftigkeit – nichts zu tun hat. Und zwar tatsächlich: rein gar nichts.
Mit dieser Ansicht oute ich mich möglicherweise als wenig weltgewandter Europäer. „Als Tonsprache wird eine Sprache definiert, in der jede Silbe eine distinktive Tonhöhe oder einen distinktiven Tonhöhenverlauf besitzt […].Sehr viele Sprachen der Erde, vielleicht sogar die Mehrzahl der Sprachen, sind Tonsprachen in diesem Sinne. Unter den europäischen Sprachen findet sich jedoch keine Tonsprache […].“ (Pétursson/Neppert: Elementarbuch der Phonetik; Helmut Buske Verlag 2002 – Seite 158)
Und so bleibe ich erst einmal in unserer Sprache.
Norm setzt falsche Schwerpunkte
Wenn bei Nocke zu lesen ist: „Die stärksten Frequenzanteile gesprochener Sprache liegen zwischen 300 Hz und 500 Hz“ (Chr. Nocke: Raumakustik im Alltag; Beuth Verlag 2019 – Seite 25) , so darf man zumindest nicht sagen, das sei – bezogen auf die Lautstärke – gänzlich falsch:
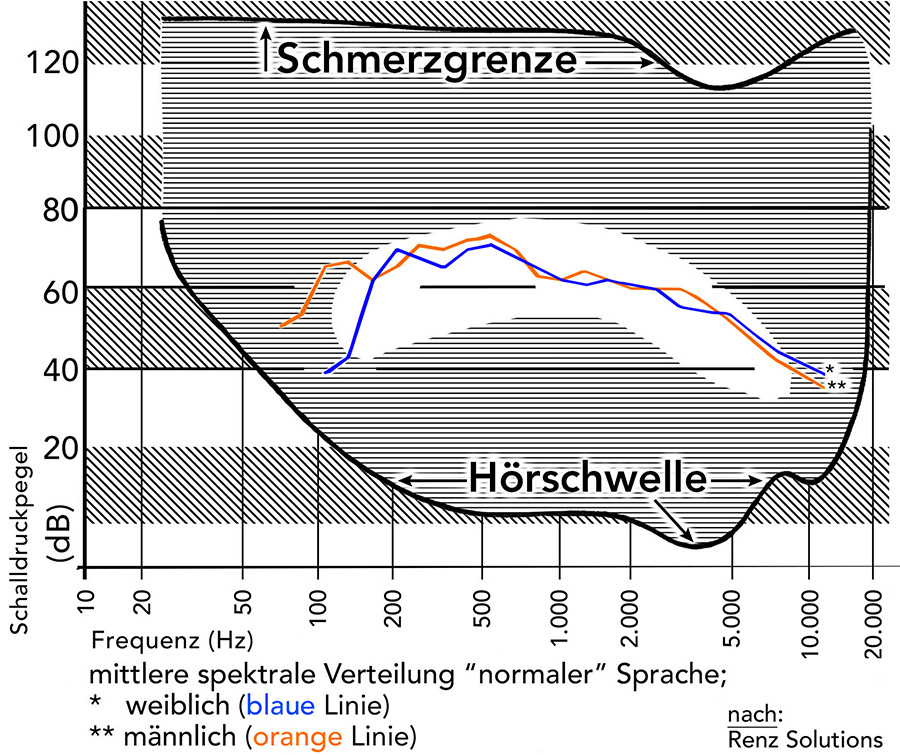
‚Renz Solutions‘ hatte in einer aus den Nuller-Jahren stammenden Publikation die Lautheiten der sprachlichen Äußerungen nach Frequenzen und nach Geschlechtern aufgeschlüsselt. Man kann demnach eine besondere Lautheit der Sprache zwischen 200 und 630 Hz anerkennen.
Das Problem jedoch ist, dass der Kodierungswert der Sprache in diesen Frequenzen kaum, nämlich nur sehr gering stattfindet. Indem ich mehrere Darstellungen zur frequenziellen Einordnung von Lauten zusammengeführt habe, zeigt sich bereits ein etwas anderes Bild. Die Nutzung mehrerer Quellen hat es mir ermöglicht, in einer eigenen grafischen Darstellung mehr Lautbildungen in nur einem Bild darzustellen.
wo Sprache erwacht:
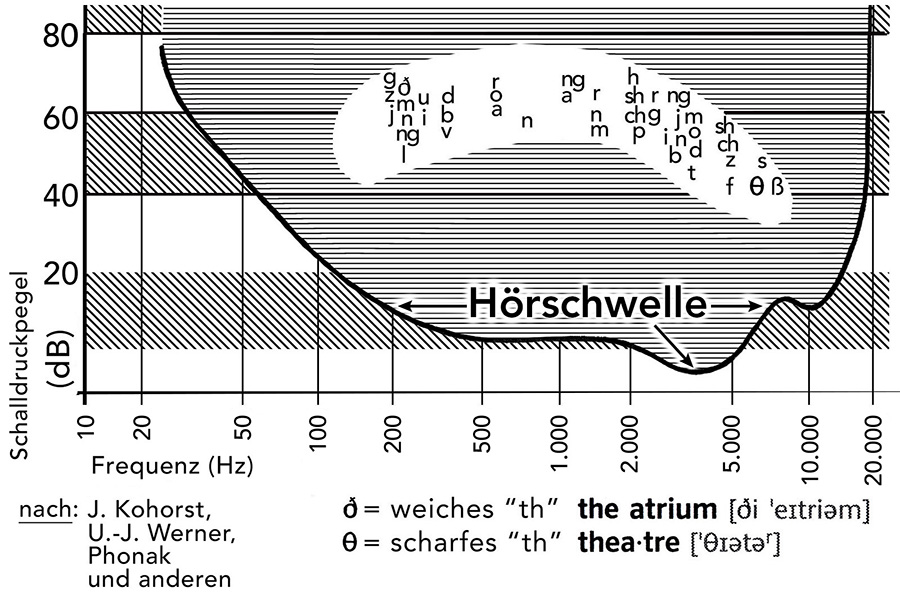
Bei Nocke heißt es nun: „[…] der für die menschliche Sprach-Kommunikation wichtige Bereich von 200 Hz bis 2.000 Hz“ (Chr. Nocke: Raumakustik im Alltag; Beuth Verlag 2019 – Seite 25). Mit dieser Feststellung und Einordnung aber fällt nicht nur gut die Hälfte der sprachlichen Kodierungen unter den Tisch – weil sie oberhalb von 2.000 Hz stattfinden. Sondern insgesamt ist das bisherige Verständnis von den Sprachlauten außerdem unvollständig bis fehlerhaft.
3 Beispiele mögen das verdeutlichen:
m und n: Beide Laute sind sog. „stimmhafte“ Konsonanten – ebenso wie alle Vokale stimmhaft sind. Aber obwohl der Mund beim „m“ geschlossen, beim „n“ leicht geöffnet ist, unterscheiden sich beide Laute kaum voneinander. Sondern vielmehr gewinnen sie ihren Ausdruck erst im Zusammenhang mit einem Vokal. Egal, ob stimmhaft gesprochen oder geflüstert: Beide Konsonanten sind genau genommen bei 200 Hz fehlerhaft eingeordnet. Erst die Geräusche im Übergang zu Vokalen prägen beide Laute erst zu eindeutigen Buchstaben aus.
beide ‚th‚: Das scharfe ‚th‘ (z. B. englisch ‚thumb‘, ‚theatre‘ …) ist korrekt bei den sehr hohen Frequenzen eingeordnet, weil es als „harter“ Lispel-Laut zwischen Zisch- und Rauschlaut verortet. Das weiche ‚th‘ (z. B. englisch ‚those‘ oder ‚together‘) beinhaltet – vergleichbar „m“ oder „n“ – überhaupt keine Kodierung. Erst im Zusammenspiel mit Vokalen wird daraus eine Lautbarkeit. Diese Lautbarkeit jedoch ist getragen von den Obertönen, nicht von der Stimme. Das weiche ‚th‘ gehört also ebenfalls nicht bei 200 Hz eingeordnet.
energiearme Sprachlaute
alle Vokale – a, e, i, o, u: Nicht nur die Tatsache, dass man Vokale auch flüstern kann, deutet darauf hin, dass sie in der Stimme nicht kodieren. Sondern es ist auch die Tatsache, dass bei gesperrtem Unterkiefer die Vokale sämtlich nicht unterscheidbar sind. So lässt sich bei fixiertem Unterkiefer die Mundhöhle nicht formen und Modulation mit der Zunge nur eingeschränkt umsetzen. Es wird deutlich, dass der Kodierungswert auch der Vokale erst über den Mundraum entsteht – und erst im Übergang vom Konsonanten zum Vokal oder vom Vokal zum Konsonanten eindeutig erkennbar wird.
So lässt sich auch leicht erkennen, dass die gesamte sprachliche Kodierung von den Obertönen getragen wird – d. h. in den oberen Mittenfrequenzen und in den hohen Frequenzen stattfindet UND stets energiearm ist…

… aber auch, dass die Phonetik in einigen Details einen verzerrten Blick auf Sprachbildung und Sprachlaute vermittelt.
Die sprachliche Kodierung ist essenziell, nämlich unabdingbar gestützt auf die oberen Mitten- und die hohen Frequenzen! DESHALB sind vollflächig bedämpfende Decken auch stets nachteilig für die Kommunikation. Das gilt schon in durchschnittlich großen Kommunikationsräumen wie etwa Klassenräumen. Und das gilt erst recht dort, wo man wegen – hingegen nicht „zugunsten“ – der Inklusion Räume besonders stark bedämpft, d. h. man die Schallenergie noch besonders stark absorbiert.
Absorption zerstört Sprache
DIN 18041:2016-03 empfiehlt ausdrücklich: „Da bei Räumen mit einem Volumen bis ca. 250 m3 keine Gefahr zur akustischen Überdämpfung besteht, kann hier eine vollflächig schallabsorbierende Decke in Kombination mit einer ebenfalls schallabsorbierenden Rückwand eingesetzt werden.“ (DIN 18041:2016-03; 5.4 – Positionierung akustisch wirksamer Flächen)
Und die Folge dieser raumakustischen Alltäglichkeit ist… ?
… dass die Räume dumpf klingen und sowohl Sprache und auch Musik in den Höhen beschnitten und detailarm wiedergeben. Dem gesprochenen Wort fehlt die nötige Plastizität. Aber aufgrund der Energiearmut auch die nötige Reichweite – schon in einem normalgroßen Klassen- oder Besprechungsraum!
Sprache übt sich früh
Hier darf nun auch ein anderes Thema nicht unerwähnt bleiben: der Spracherwerb in KiTas. Sprache lernen ist kaum irgendwo so grundlegend wichtig, wie für Kinder im KiTa-Alter.
Zugleich ist die Klarheit von Sprache sehr gering, wo man „im Zweifelsfall“ (DIN 18041) mit Absorption großzügig umgeht. Denn dann ist das gegenseitige Verstehen davon abhängig, dass Hörende sich aus den Lautfragmenten Wörter und Sätze vervollständigen können. Zum einen leidet darunter die Konzentration, je weniger die Dekodierung unterbewusst und ohne Anstrengung abgearbeitet wird. Zum anderen erfordert das eine bereits hohe sprachliche Kompetenz in der gehörten Sprache.
Es führt aber auch dazu, dass Sprache mangelhaft erlernt wird. Denn – unterbewusst – imitiert das Kind das gehörte Sprachsignal als nachahmenswert und korrekt. Ist die Sprache aber unklar übertragen worden (durch schlechte Raumakustik + zu starke Bedämpfung), so wird auch ein unklares und dumpfes Sprachsignal immitiert. So gewöhnen sich Kinder in der wichtigsten Prägungsphase eine undeutliche Sprache mit dem Bewusstsein an, die Erwachsenenwelt perfekt zu imitieren.
… oder Sprache zu verstehen, gelingt ohnehin nur noch bruchstückhaft, wenn der Hörsinn in der einen oder anderen Weise beeinträchtigt ist. Hier werden dann die Belange der Inklusion berührt.
Schon etwa ab der Mitte solcher Räume (z. B. ein durchschnittlich großer Klassenraum mit ca. 200 m3 Raumvolumen) reicht der Direktschall bei Weitem nicht mehr aus, um für einen klaren sprachlichen Austausch überall im Raum mit der nötigen Reinheit und Transparenz vernommen werden zu können.